
*** 아래의 내용은 패스트 캠퍼스 자료구조 강의 자료(이준희 강사님 저)를 강의를 들으면서 정리한 내용입니다. ***
1. 큐
- 가장 먼저 넣은 데이터를 가장 먼저 꺼낼 수 있는 구조
- 음식점에서 가장 먼저 줄을 선 사람이 제일 먼저 음식점에 입장하는 것과 동일
- FIFO(First-In, First-Out) 또는 LILO(Last-In, Last-Out) 방식으로 스택과 꺼내는 순서가 반대
어디에 큐가 많이 쓰일까?
- 멀티 태스킹을 위한 프로세스 스케쥴링 방식을 구현하기 위해 많이 사용됨 (운영체제 참조)

출처: http://www.stoimen.com/blog/2012/06/05/computer-algorithms-stack-and-queue-data-structure/
2. 스택
- 스택은 LIFO(Last In, Fisrt Out) 또는 FILO(First In, Last Out) 데이터 관리 방식을 따름
- LIFO: 마지막에 넣은 데이터를 가장 먼저 추출하는 데이터 관리 정책
- FILO: 처음에 넣은 데이터를 가장 마지막에 추출하는 데이터 관리 정책
- 대표적인 스택의 활용
컴퓨터 내부의 프로세스 구조의 함수 동작 방식
- 주요 기능
push(): 데이터를 스택에 넣기
pop(): 데이터를 스택에서 꺼내기
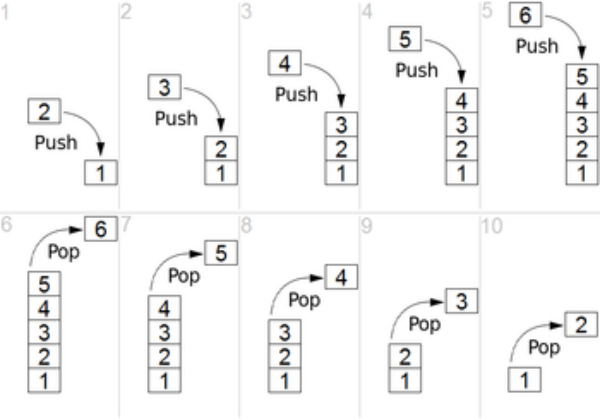
* 스택 구조와 프로세스 스택
- 스택 구조는 프로세스 실행 구조의 가장 기본
- 함수 호출시 프로세스 실행 구조를 스택과 비교해서 이해 필요
- 장점
구조가 단순해서, 구현이 쉽다.
데이터 저장/읽기 속도가 빠르다.
- 단점 (일반적인 스택 구현시)
데이터 최대 갯수를 미리 정해야 한다.
파이썬의 경우 재귀 함수는 1000번까지만 호출이 가능함
저장 공간의 낭비가 발생할 수 있음
미리 최대 갯수만큼 저장 공간을 확보해야 함.
스택은 단순하고 빠른 성능을 위해 사용되므로, 보통 배열 구조를 활용해서 구현하는 것이 일반적임. 이 경우, 위에서 열거한 단점이 있을 수 있음
3. 링크드 리스트
- 연결 리스트라고도 함
- 배열은 순차적으로 연결된 공간에 데이터를 나열하는 데이터 구조
- 링크드 리스트는 떨어진 곳에 존재하는 데이터를 화살표로 연결해서 관리하는 데이터 구조
- 본래 C언어에서는 주요한 데이터 구조이지만, 파이썬은 리스트 타입이 링크드 리스트의 기능을 모두 지원
- 링크드 리스트 기본 구조와 용어
노드(Node): 데이터 저장 단위 (데이터값, 포인터) 로 구성
포인터(pointer): 각 노드 안에서, 다음이나 이전의 노드와의 연결 정보를 가지고 있는 공간
링크드 리스트의 장단점 (전통적인 C언어에서의 배열과 링크드 리스트)
- 장점
미리 데이터 공간을 미리 할당하지 않아도 됨
배열은 미리 데이터 공간을 할당 해야 함
- 단점
연결을 위한 별도 데이터 공간이 필요하므로, 저장공간 효율이 높지 않음
연결 정보를 찾는 시간이 필요하므로 접근 속도가 느림
중간 데이터 삭제시, 앞뒤 데이터의 연결을 재구성해야 하는 부가적인 작업 필요
4. 해쉬 테이블
해쉬 구조
- Hash Table: 키(Key)에 데이터(Value)를 저장하는 데이터 구조
- Key를 통해 바로 데이터를 받아올 수 있으므로, 속도가 획기적으로 빨라짐
- 파이썬 딕셔너리(Dictionary) 타입이 해쉬 테이블의 예: Key를 가지고 바로 데이터(Value)를 꺼냄
- 보통 배열로 미리 Hash Table 사이즈만큼 생성 후에 사용 (공간과 탐색 시간을 맞바꾸는 기법)
- 단, 파이썬에서는 해쉬를 별도 구현할 이유가 없음 — 딕셔너리 타입을 사용하면 됨
알아둘 용어
- 해쉬(Hash): 임의 값을 고정 길이로 변환하는 것
- 해쉬 테이블(Hash Table): 키 값의 연산에 의해 직접 접근이 가능한 데이터 구조
- 해싱 함수(Hashing Function): Key에 대해 산술 연산을 이용해 데이터 위치를 찾을 수 있는 함수
- 해쉬 값(Hash Value) 또는 해쉬 주소(Hash Address): Key를 해싱 함수로 연산해서, 해쉬 값을 알아내고, 이를 기반으로 해쉬 테이블에서 해당 Key에 대한 데이터 위치를 일관성있게 찾을 수 있음
- 슬롯(Slot): 한 개의 데이터를 저장할 수 있는 공간
- 저장할 데이터에 대해 Key를 추출할 수 있는 별도 함수도 존재할 수 있음
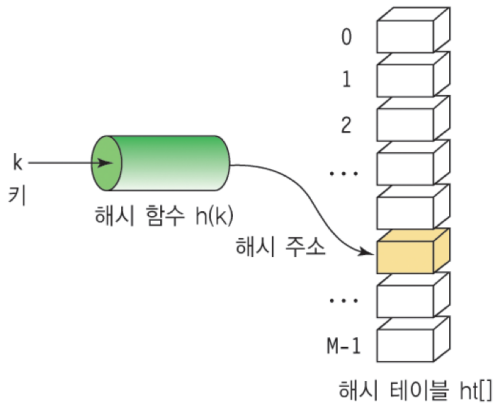
해쉬 테이블의 장단점과 주요 용도
- 장점
데이터 저장/읽기 속도가 빠르다. (검색 속도가 빠르다.)
해쉬는 키에 대한 데이터가 있는지(중복) 확인이 쉬움
- 단점
일반적으로 저장공간이 좀더 많이 필요하다.
여러 키에 해당하는 주소가 동일할 경우 충돌을 해결하기 위한 별도 자료구조가 필요함
- 주요 용도
검색이 많이 필요한 경우
저장, 삭제, 읽기가 빈번한 경우
캐쉬 구현시 (중복 확인이 쉽기 때문)
충돌(Collision) 해결 알고리즘 (좋은 해쉬 함수 사용하기)
해쉬 테이블의 가장 큰 문제는 충돌(Collision)의 경우입니다. 이 문제를 충돌(Collision) 또는 해쉬 충돌(Hash Collision)이라고 부릅니다.
1. Chaining 기법
- 개방 해슁 또는 Open Hashing 기법 중 하나: 해쉬 테이블 저장공간 외의 공간을 활용하는 기법
- 충돌이 일어나면, 링크드 리스트라는 자료 구조를 사용해서, 링크드 리스트로 데이터를 추가로 뒤에 연결시켜서 저장하는 기법
2. Linear Probing 기법
- 폐쇄 해슁 또는 Close Hashing 기법 중 하나: 해쉬 테이블 저장공간 안에서 충돌 문제를 해결하는 기법
- 충돌이 일어나면, 해당 hash address의 다음 address부터 맨 처음 나오는 빈공간에 저장하는 기법
- 저장공간 활용도를 높이기 위한 기법
3. 빈번한 충돌을 개선하는 기법
- 해쉬 함수을 재정의 및 해쉬 테이블 저장공간을 확대
참고: 해쉬 함수와 키 생성 함수
- 파이썬의 hash() 함수는 실행할 때마다, 값이 달라질 수 있음
- 유명한 해쉬 함수들이 있음: SHA(Secure Hash Algorithm, 안전한 해시 알고리즘)
- 어떤 데이터도 유일한 고정된 크기의 고정값을 리턴해주므로, 해쉬 함수로 유용하게 활용 가능
시간 복잡도
- 일반적인 경우(Collision이 없는 경우)는 O(1)
- 최악의 경우(Collision이 모두 발생하는 경우)는 O(n)
- 해쉬 테이블의 경우, 일반적인 경우를 기대하고 만들기 때문에, 시간 복잡도는 O(1) 이라고 말할 수 있음
검색에서 해쉬 테이블의 사용 예
- 16개의 배열에 데이터를 저장하고, 검색할 때 O(n)
- 16개의 데이터 저장공간을 가진 위의 해쉬 테이블에 데이터를 저장하고, 검색할 때 O(1)
*** 위의 내용은 패스트 캠퍼스 자료구조 강의 자료(이준희 강사님 저)를 강의를 들으면서 정리한 내용입니다. ***
'자료구조' 카테고리의 다른 글
| [자료구조] 트리, 힙, 시간복잡도 (0) | 2021.11.16 |
|---|
